



EPIA: Easily Parallel Instruction Architecture
GitHub: github.com/matrixsmaster/EPIA
En slank, åpen NPU for lokal inferens og finjustering
Moderne robotikk krever endelig seriøs, privat AI på kanten: reaksjoner under 100 ms, ingen ustabile uplinks, og ingen data som forlater roboten. Den nåværende tilnærmingen – lukkede GPUer, tunge runtime-miljøer og sky-backups – øker kostnad, latens og leverandørlås. EPIA snur dette på hodet: en åpen, leverandørnøytral NPU som du kan revidere, portere og utvide. Den gir team uavhengighet fra Nvidia, deterministisk latens under stramme strømkrav, og en RISC-V-stil økosystemsti hvor alle kan bygge verktøy, kompilatorer og kjerner uten å be om tillatelse. Dette gir bred deltakelse, robuste forsyningskjeder og rask iterasjon for virkelige roboter.
Hvorfor EPIA?
- Bygget for ekte edge AI: 64-bits datapath, liten kontrollplan og et minnesystem som effektivt streamer tensorer.
- Enkel parallellisme: én instruksjon (
ppu) fordeler koden din til N arbeidstråder; en liten systemkontroller holder kjernene opptatt. - Førsteklasses kvantisering: Scaled Dot-Product Unit (SDPU) akselererer blokkerte, kvantiserte vektorer for moderne lav-bit inferens.
- Ingen oppblåsing: en liten, ortogonal ISA med argumentbredde-modifikatorer og en ren flaggmodell. Lett å håndjustere; lett å kodegenerere.
- Komponerbar: fleksibel I/O-kontroller og minnekontroller gjør det enkelt å integrere EPIA på kort med superrask DDR, QSPI/Flash, SDIO, samt vanlige lavhastighetsperiferier.
Typisk bruk: full AI-stack på robot
En humanoid mottar kontinuerlig sensordata: kameraer mates til en VLM for scene-forståelse; mikrofoner mates til en Whisper-klasse ASR; transkripsjon og visuell kontekst går til en LLM for resonnement; resultater forgrener seg til flere strømmer (gest-/ansiktskontroll, display/UI, logging), mens en stor handlingsmodell planlegger høy-nivå oppførsel; til slutt genererer en rask TTS tale. Med EPIA mapper hvert trinn tydelig til én NPU-“rolle”. Kvantiserte matmuls og attention-lag kjører på SDPU; PPU-splitt håndterer batch-/sekvens-shards; Core0 gjør de små sekvensielle oppgavene; DMA streamer tensorer over MINI, slik at beregning aldri stopper. Sekvensielle trinn (f.eks. ASR-dekoding eller TTS-vokoding) kjøres tidsdelt på én brikke; høyt parallelle trinn (VLM attention-blokker, LLM-lag, handlingsmodell-inferens) fordeles over flere brikker for høy gjennomstrømning.
Skaler fra slank til ekstrem
I minimalistisk bygg erstatter én EPIA-chip vanlig SoC+GPU-pakke: Core0 orkestrerer, PPU/SDPU behandler kvantiserte kjerner, MemC paginerer vekter fra DDR/SDIO, og IOC kommuniserer direkte med kroppmoduler over I²C/UART/QSPI - ingen gigantisk driverstack. I high-end bygg fordeles oppgaver over flere EPIAer: én (eller flere) for VLM, én for ASR+TTS, én for LLM/policy, én for handlingsplanlegger. Du får pipeline-parallellisme, forutsigbar latens per trinn, og full autonomi på roboten – ingen internett, ingen dataeksfiltrering, bare rask, lokal intelligens med enkel kobling til resten av kroppen via IOC.
Arkitektur på et øyeblikk
EPIA er en fleksibel arkitektur med teoretisk nærmest ubegrenset antall kjerner. EPIA-systemet kan instansieres med et vilkårlig antall kjerner som passer i målplattformen (FPGA eller ASIC).
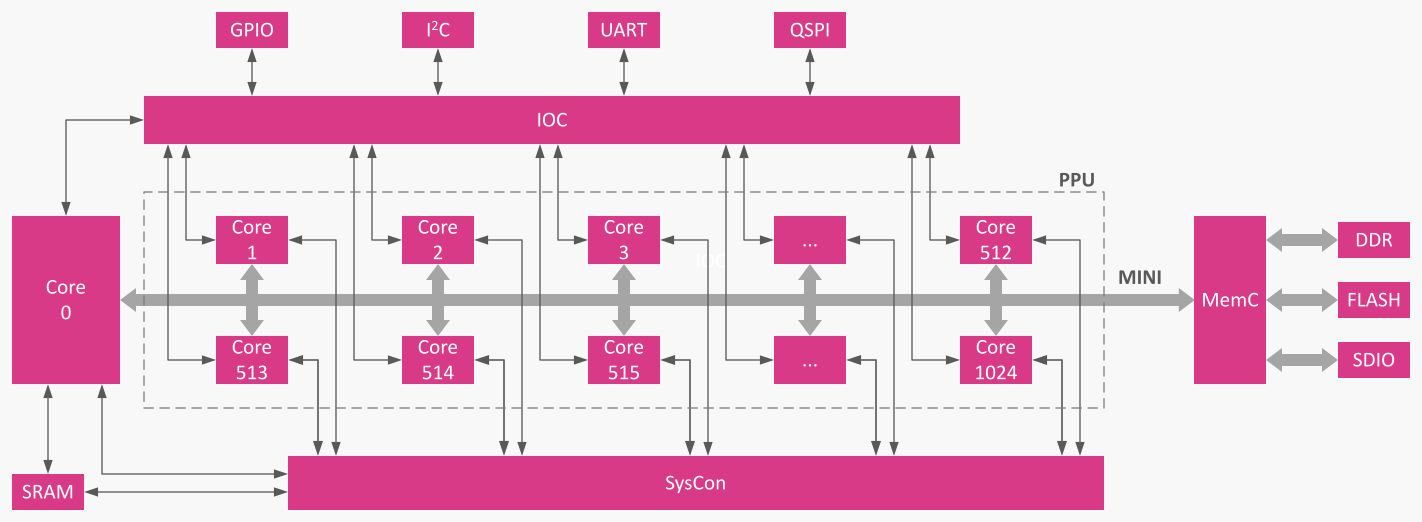
EPIA organiseres rundt en MINI-systembuss (Memory Interface for Neural Inference). En liten System Controller (SysCon) planlegger arbeid og arbiterer ressurser mellom N+1 identiske kjerner (Core0 pluss en Parallel Processing Unit, PPU). En Fleksibel Memory Controller (MemC) streamer til/fra DDR/Flash/SDIO, mens en I/O Controller (IOC) håndterer atomære overføringer på I²C, UART, QSPI osv.
Core0 kjører typisk de sekvensielle delene av programmet, mens PPU-kjernene behandler parallelle regioner. Når en ppu-instruksjon oppdages, deles utførelsen i k tråder (du velger k). Hvis det er færre fysiske kjerner enn tråder, kjører SysCon resten så snart en kjerne blir ledig – ingen ekstra kodebehandling kreves.
Kjernemikroarkitektur
Kjernene er homogene, deler samme arkitektur, og består av de samme nøkkelkomponentene. Core0 har også samme arkitektur, men med en noe lengre pipeline.
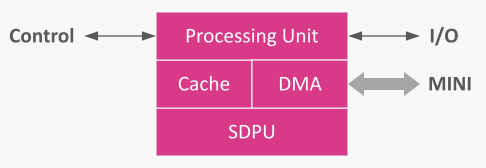
Hver kjerne har:
- en Processing Unit som utfører instruksjonene,
- en DMA-motor for å trekke/push tensorer over MINI,
- en Cache optimalisert for streaming av tensorer og håndtering av tråd-lokale data, og
- SDPU-blokken for kvantiserte skalerte dot-produkt-beregninger.
Den uniforme kjernekonstruksjonen holder planlegging enkel og gjør ytelsen forutsigbar.
Programmeringsmodell
EPIA bruker en kompakt, ortogonal ISA med bredde-modifiserte mnemonics: legg til b/h/w/d for å operere på 8/16/32/64-bits data (standard er 64-bits). Eksempel: movb, cmpw, addd. Det finnes heltalls-, flyttall-, logikk/shift- og kontrollflytfamilier, samt I/O og DPU-tilgangsinstruksjoner.
Noen små regler gjør modellen både uttrykksfull og sikker på lav-bit pipelines:
- Eksplisitt bredde er en funksjon. Du velger hvor bred hver operasjon leser/skriver – perfekt for tettpakkede tensorer og mixed-precision flows. Konverteringer er eksplisitte (
itf,fti), medfti*som leser 32-bits float og skriver den valgte heltallsbredden. (fp16-støtte kommer snart) - Alle operander er minne-residente. Maskinvare-cache og DMA gjør dette mulig og holder ISA kompakt.
- Minimal flaggbruk.
Z/L/G/Egir forutsigbar branching uten skjulte overraskelser.
For parallell kode markerer clo-instruksjonen lokasjoner som tråd-lokale clobbers for å forhindre cache-kontaminering når flere tråder bruker samme midlertidige slotter. Cachen gjør disse tilgangen ekstremt raske og sikkert isolerte per kjerne.
Parallell utførelse som passer i hodet ditt
EPIA tillater enkel og intuitiv parallellisering fra programvarens perspektiv.
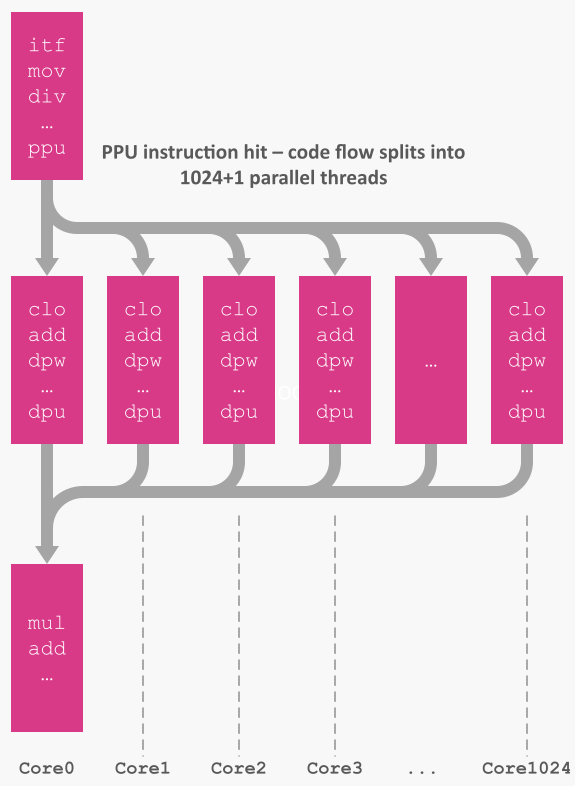 Når en
Når en ppu-instruksjon utløses, forkes koden din bokstavelig talt i NThreads deler. Hver tråd får en liten sekvensiell ID (0..N-1) skrevet til et valgt minneområde, som kan brukes for stride eller blokkindeksering. Trådene kjører til de når din barrier address (eller hlt), deretter returnerer kontrollen til Core0 ved neste instruksjon etter ppu.
Denne designen gir fordelene av en trådpool – uten å måtte opprette eller administrere en. Hvis NThreads overstiger tilgjengelige kjerner, planlegger SysCon overheng sømløst. I praksis kan du velge et grid/block som matcher tensoren din og la maskinvaren gjøre resten.
Merk: sjekk våre LLM-inferens eller 3D-rendering demoer for å se hvor enkelt det er å programmere med PPU!
SDPU: kvantisert matematikk uten smerte
Moderne inferens er kvantisert. EPIA integrerer dette med Scaled Dot-Product Unit:
- Per-blokk skala håndtering for vanlige kvantiserte formater.
- Registergrensesnitt (
dpw/dpr) for å sette opp blokker, formater og former. - Enkelt instruksjon (
dpu) for å starte operasjonen og returnere én skalar. - Cache-prefetching optimalisert for effektiv streaming av pakkede vektorer.
Kombiner SDPU med PPU fan-out, og du får høy gjennomstrømning på attention, matmul og konvolusjonsliknende dot-produktkjerner.
Minne & I/O
- MINI-bus er optimalisert for tensor-streaming og DMA-burstoverføringer.
- MemC abstraherer DDR/Flash/SDIO slik at du enkelt kan boot, paginere modeller og lagre status.
- IOC gir atomær, ordnet I/O på vanlige innebygde lenker (I²C, UART, QSPI) slik at enheter kan styres eller logges i takt med beregningen.
Utvikleropplevelse
- Liten ISA-overflate du kan lære på en ettermiddag.
- Bredde-suffiks-disciplin lar deg pakke minne tett og velge nøyaktig hvor truncation/extension skjer.
- Deterministiske flagg og en klar
jmp/jif-modell gjør kontrollflyten åpenbar. - Tråd-lokale clobbers (
clo) og enkel parallell-splitt (ppu) eliminerer vanlige fallgruver i parallellprogrammering. - Rette-linje-kjerner er enkle å kodegenerere fra en kompilator eller finjustere manuelt når du trenger absolutt kontroll.
Hvis du liker å skrive kompakte kjerner – eller generere dem – vil EPIA føles som en vennlig, moderne etterkommer av klassiske vektormaskiner, minus bagasjen, med ekstra ytelse og skalerbarhet.
Typiske arbeidsbelastninger
- LLM/VLM-inferens på edge, med modeller av betydelig størrelse (7B+)
- Lokal finjustering med mixed-precision accumulatorer
- Signalbehandling og feature-ekstraksjon der skalerte dot-produkt dominerer
- Robotikk/embedded AI som krever deterministisk timing og kompakte binærfiler, samtidig som store modeller må prosesseres
Hva du kan forvente
EPIA prioriterer forutsigbarhet og komponerbarhet fremfor “gjør alt”-kompleksitet. Det betyr at du får:
- Nesten lineær skalering på ekstremt parallelle kjerner,
- Stabil gjennomstrømning på kvantisert matematikk via SDPU,
- Tett kontroll over minnebåndbredde, og
- En kodebase du faktisk kan forstå.
Hvis du verdsetter små, presise verktøy for ekte edge AI, er EPIA for deg.