


EPIA:易并行指令架构
GitHub: github.com/matrixsmaster/EPIA
一款轻量级开源 NPU,用于设备端推理和微调
现代机器人技术终于需要在边缘实现强大、私有的 AI:响应时间低于 100 毫秒,无不稳定的上行链路,且数据绝不离开机器人。目前的方案—封闭的 GPU、重量级运行时以及云端回退—增加了成本、延迟和锁定风险。EPIA 颠覆了这一模式:一个开源、厂商中立的 NPU,您可以审计、移植和扩展。它让团队摆脱对 Nvidia 的依赖,在严格功耗预算下实现确定性延迟,并提供 RISC-V 风格的生态路径,任何人都可以在无需许可的情况下构建工具、编译器和核心。这就是我们实现广泛参与、弹性供应链以及现实机器人快速迭代的方法。
为什么选择 EPIA?
- 为真正的边缘 AI 构建:64 位数据通路、微型控制平面,以及高效流式处理张量的内存系统。
- 简单并行:一条指令(
ppu)将代码分发到 N 个工作线程;微型系统控制器保持核心繁忙。 - 一流量化支持:缩放点积单元 (SDPU) 加速现代低位推理的按块缩放量化向量运算。
- 无臃肿:小型、正交的 ISA,带参数宽度修饰符及简洁标志模型。易于手动调优;易于代码生成。
- 可组合:灵活的 I/O 控制器和内存控制器使 EPIA 能够轻松集成到配备超高速 DDR、QSPI/Flash、SDIO 以及常用低速外设的板卡中。
典型用例:完整的机器人端 AI 栈
人形机器人持续采集传感器数据:摄像头提供 VLM 进行场景理解;麦克风提供 Whisper 级 ASR;转录文本和视觉上下文输入 LLM 进行推理;结果分支到多个流(手势/面部控制、显示/UI、日志记录),同时大型动作模型规划高层行为;最后,快速 TTS 生成语音。使用 EPIA,每个阶段可清晰映射到一个 NPU“角色”。量化矩阵乘法和注意力层在 SDPU 上运行;PPU 分发处理批量/序列片段;Core0 处理小型顺序任务;DMA 通过 MINI 流式传输张量,确保计算不断供。自然顺序的阶段(如 ASR 解码或 TTS 声码)在单芯片上时间片执行;高度并行的阶段(VLM 注意力块、LLM 层、动作模型推理)在多个芯片上分发以提高吞吐量。
从精简到高性能的扩展
在最小化配置中,一颗 EPIA 芯片即可替代常规 SoC+GPU 组合:Core0 协调,PPU/SDPU 处理量化内核,MemC 从 DDR/SDIO 分页权重,IOC 通过 I²C/UART/QSPI 直接与身体模块通信—无需庞大驱动栈。在高端配置中,可将任务分散到多颗 EPIA:一颗(或多颗)用于 VLM,一颗用于 ASR+TTS,一颗用于 LLM/策略,一颗用于动作规划。实现流水线并行、每阶段可预测延迟,并实现完整机器人端自治—无需互联网,无数据外泄,仅通过 IOC 与机器人其余部分的简单连线,实现快速、本地智能。
架构概览
EPIA 是一个灵活的架构,理论上可拥有近乎无限数量的核心。EPIA 系统可实例化任意数量的核心,以适配目标 FPGA 或 ASIC。
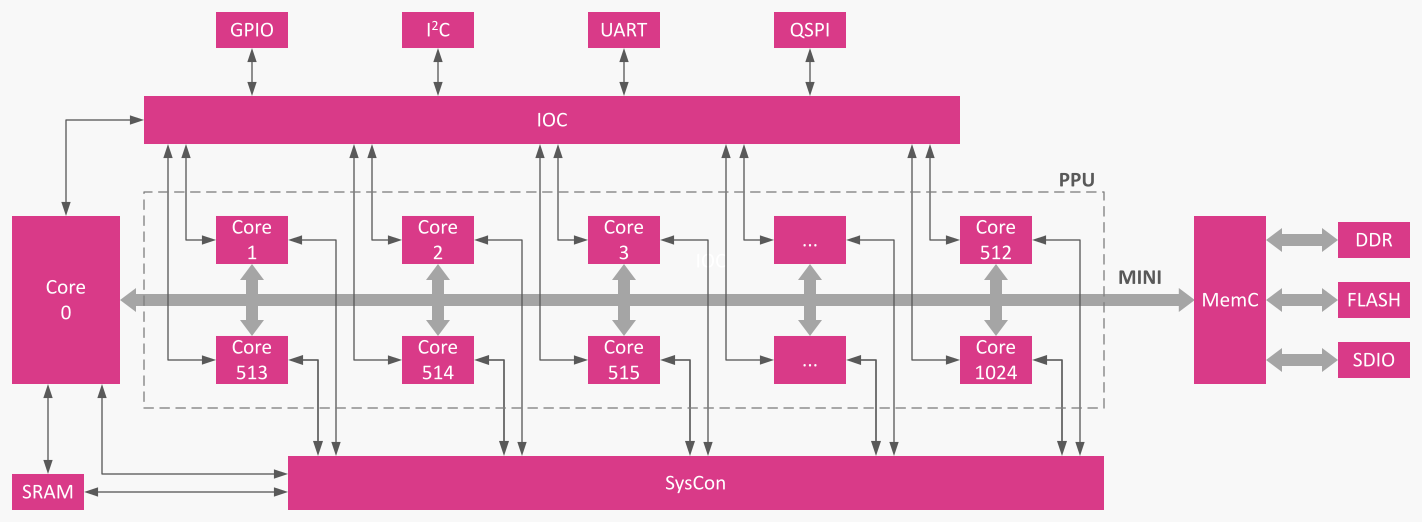
EPIA 围绕 MINI 系统总线(Memory Interface for Neural Inference)组织。小型 系统控制器 (SysCon) 调度工作并在 N+1 个相同核心(Core0 加 并行处理单元 PPU)间仲裁资源。灵活内存控制器 (MemC) 处理 DDR/Flash/SDIO 流,而 I/O 控制器 (IOC) 处理 I²C、UART、QSPI 等的原子传输。
Core0 通常运行程序的顺序部分,而 PPU 核心处理并行区域。当遇到 ppu 指令时,执行分裂为 k 个线程(用户选择 k)。如果物理核心少于线程数,SysCon 会在核心释放时立即调度剩余线程—无需在代码中添加额外结构。
核心微架构
核心同构,共享相同架构,并包含相同关键组件。Core0 架构相同,仅流水线略长。
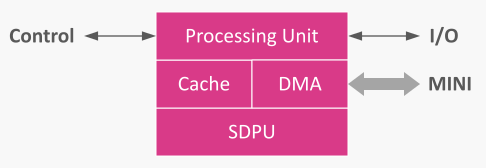
每个核心包含:
- 处理单元,执行指令,
- DMA 引擎,通过 MINI 拉取/推送张量,
- 缓存,针对流式张量及线程本地数据优化,
- SDPU 块,用于量化缩放点积计算。
统一的核心设计简化调度并使性能可预测。
编程模型
EPIA 使用紧凑、正交的 ISA,带 宽度修饰助记符:附加 b/h/w/d 操作 8/16/32/64 位数据(默认 64 位)。示例:movb、cmpw、addd。包括整数、浮点、逻辑/移位、控制流系列,以及 I/O 和 DPU 访问指令。
一些小规则使该模型在低位流水线中既表达力强又安全:
- 显式宽度是特性。 可选择每个操作的读写宽度—非常适合紧凑张量和混合精度流。转换显式 (
itf,fti),fti*读取 32 位浮点并写入所选整数宽度。(即将支持 fp16) - 所有操作数均驻留内存。 硬件缓存和 DMA 使其可行,并保持 ISA 简洁。
- 标志最小化。
Z/L/G/E提供可预测分支,无隐藏惊喜。
对于并行代码,clo 指令标记为 线程本地覆盖,防止多线程使用相同临时槽(迭代器、临时变量、累加器)时的缓存交叉污染。缓存使这些访问高速且对每个核心安全隔离。
直观的并行执行
EPIA 从软件角度提供非常简单直观的并行化方式。
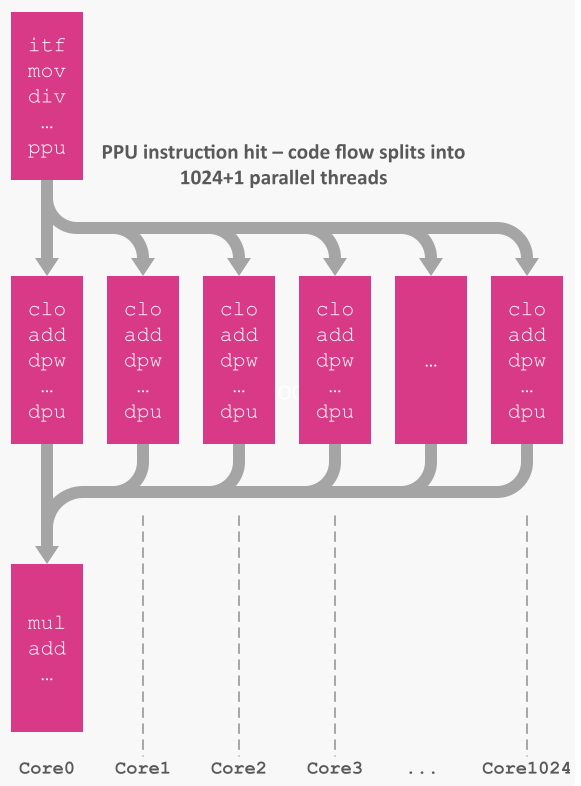
当 ppu 指令触发时,代码 直接分叉 为 NThreads 片段。每个线程获得一个小型顺序 ID(0..N‑1),写入用户选择的内存位置,可用于步幅或块索引。线程运行至 屏障地址(或 hlt),然后控制返回 Core0,执行 ppu 之后的下一条指令。
该设计带来线程池的好处—无需创建或管理线程池。如果 NThreads 超过可用核心,SysCon 会透明调度溢出线程。实际上,只需选择与张量匹配的网格/块形状,硬件即可完成剩余工作。
提示:查看我们的 LLM 推理或 3D 渲染演示,体验 PPU 编程的简便性!
SDPU:轻松量化计算
现代推理采用量化。EPIA 内置 缩放点积单元 (SDPU):
- 按块缩放,处理常见量化格式。
- 寄存器接口(
dpw/dpr)设置块、格式和形状。 - 单条指令(
dpu)触发操作并返回单个标量结果。 - 缓存预取,优化打包向量流式处理。
SDPU 配合 PPU 分发,可在注意力、矩阵乘法和卷积类点积内核上实现高持续吞吐量。
内存与 I/O
- MINI 总线优化张量流和 DMA 突发传输。
- MemC 抽象 DDR/Flash/SDIO,方便启动、模型分页及状态检查点管理。
- IOC 提供常用嵌入式接口(I²C、UART、QSPI)的原子、有序 I/O,使设备可与计算同步指令或日志记录。
开发者体验
- 小型 ISA 范围,可在一下午记忆完毕。
- 宽度后缀规范,可紧凑存储内存,精确控制截断/扩展位置。
- 确定性标志及清晰
jmp/jif模型,使控制流明显。 - 线程本地覆盖(
clo)及单操作并行分发(ppu)消除常见并行编程陷阱。 - 直线内核,编译器易生成,手动调优可完全控制。
如果您喜欢编写紧凑内核或生成内核,EPIA 会让您感觉像经典矢量机的现代友好继承者—无负担,却具备高性能与可扩展性。
典型工作负载
- 边缘 LLM/VLM 推理,处理大规模模型(7B+)
- 设备端混合精度微调
- 信号处理及 特征提取,以缩放点积为主
- 机器人/嵌入式 AI,需要确定性时序和紧凑二进制,同时处理大模型
预期效果
EPIA 倾向于 可预测性和可组合性,而非“万事俱备”复杂性。也就是说,您将获得:
- 在极易并行内核上的近线性扩展,
- 通过 SDPU 实现量化计算的稳定吞吐,
- 对内存带宽的严格控制,
- 可真正理解的代码库。
如果您重视小巧、精确的边缘 AI 工具,EPIA 非常适合您。